Modeling agricultural realities to support development decisions - Tropentag 2017 presentation10/10/2017
0 Comments
 Making predictions about which development projects will deliver value for money hinges on investing in accurate and attuned assessments. Here, a volunteer farmer trainer in Kenya explains how to grow fodder for dairy cattle. Photo Credit: ICRAF/Sherry Odeyo Making predictions about which development projects will deliver value for money hinges on investing in accurate and attuned assessments. Here, a volunteer farmer trainer in Kenya explains how to grow fodder for dairy cattle. Photo Credit: ICRAF/Sherry Odeyo By Marianne Gadeberg and Eike Luedeling
This post was first published on WLE's Thrive blog here. When development workers congregate to discuss solutions and innovations, there’s often one big elephant in the room: a lot of development projects don’t work. It is an uncomfortable and, I suspect for many, truly frustrating truth that hard efforts to combat poverty and increase food security often don’t pay off. In 2011, the World Bank evaluated 86 projects and found that 41% had “non-positive outcomes.”Unfortunately, this is not an example that stands alone, and the trend understandably has project funders and investors keen to ensure that future projects deliver value for money. At the same time, development projects keep getting more and more complex as realization grows that today’s challenges call for integrated solutions that can balance trade-offs and synergies between sectors and scales. So how can we, especially considering complexity and uncertainties, attain a better assessment of what might work and what might not? A statistical model that can calculate return on investment A recently published paper proposes a new, general framework that allows for calculating costs, returns and risks of development projects over their lifetimes. The framework is based on Bayesian network modeling, which can be used to predict probable outcomes of complex processes, especially ones with many unknown factors. One helpful feature of Bayesian networks is the option to integrate expert knowledge with data, which is especially useful in places where data is scarce, such as in developing countries. Since it can also be costly to collect large amounts of data for individual projects, whereas expert knowledge is often more easily available, using Bayesian networks could prove a cost-effective way to assess development projects. Decision makers can use the framework by entering values related to project budget, impact and risks into the model, expressed either as data ranges that represent their level of certainty about the values or as precise numbers. Once the model is populated, it can calculate the costs, benefits and return on investment over a certain period, while considering the given levels of uncertainty. Because the model can be continuously updated, as new information becomes available, the authors suggest that it can be a powerful tool for project funders and implementers to evaluate projects’ current and likely future performance. Considering and addressing uncertainties The authors thus expect that the framework they propose can support decision makers through a development project’s lifetime. But, it’s worth highlighting their note on project planning: Because the model allows for detailing the degree of uncertainty of different risk factors, it also enables users to distinguish between important and less important unknowns. Making this distinction essentially allows implementers to adjust project designs to reduce potentially important risks and improve the chances of obtaining more favorable outcomes. Research has shown that decision makers tend to overestimate the amount of data needed to make sound decisions, when in fact making strategic efforts to increase certainty on some, important factors could significantly improve the accuracy of probability assessments. Plans to expand the framework are underway, allowing decision makers to determine where to invest in a little more data to make the model a lot more useful for selecting and planning development projects with high likelihoods of success. With such an array of potential benefits, you would expect development professionals to be lining up to put this project assessment framework into use, but so far uptake of the methodology has been slow. Establishing new methods takes time The researchers behind the framework note that the World Bank has expressed concern that the percentage of its projects justified by cost-benefit analysis – described as the most basic of project assessment tools – has been declining in the past several decades. Supposedly, this decline is in part due to the difficulty in applying cost-benefit analysis in situations where planners have little clarity on either the benefits or the costs of their projects. Bayesian networks are well suited to address uncertainties about benefits and costs due to their ability to work without precise numbers and to incorporate expert knowledge. At present, however, most development professionals and researchers are unfamiliar with this methodology. Some are also uncomfortable with the reliance on expert assessments and the inclusion of cause-effect relationships that haven’t been confirmed in controlled experiments. It may therefore be a while before Bayesian networks are widely used in development planning. Nonetheless, development professionals, and researchers stand to gain a lot from exploring the potential of Bayesian networks to provide practical decision support. These tools have been successful in solving practical problems and providing decision-relevant answers in many other disciplines, including computer science, public health, military operations, legal reasoning and natural resource management. Bayesian networks can help development professionals figure out what will actually work, which in itself could provide a massive return for a comparatively small investment. Training decision analysts who could work as part of development teams could generate large returns in terms of increased impact and better use of development resources. The question that remains is whether the investors and donors, who are calling for stronger guarantees that projects will succeed, are willing to dedicate the time and funds required.  How does resource competition with trees affect growth of the Ethiopian signature grain tef? A probabilistic approach can aid in modelling complex agroforestry systems. Photo by Eike Luedeling/ICRAF How does resource competition with trees affect growth of the Ethiopian signature grain tef? A probabilistic approach can aid in modelling complex agroforestry systems. Photo by Eike Luedeling/ICRAF By Eike Luedeling, Senior Decision Analyst with the Land Health Decisions program of World Agroforestry Centre (ICRAF)
Global food and development policies are increasingly being supported by crop models, but current modelling approaches are unfit for this purpose. The models in use, many of which were developed in the 1970s and 1980s for high-input monoculture systems, ignore critically important aspects of sustainable agriculture. And they do not work for complex agricultural landscapes common in developing countries, systems in which trees are integrated with crops, and which, in addition to crop yields, bring numerous benefits to people and the environment. A shift towards more holistic crop modelling is urgently needed. If crop models continue to neglect systems and outcomes that cannot be modeled with precision, their use will keep directing us towards purely yield-optimizing systems that perform poorly with regard to critical development objectives such as ecological sustainability and social fairness. Special Think Piece, first published on ICRAF's blog here. I recently attended the first major meeting of the global crop modelling community in a long time — the International Crop Modelling Symposium held in Berlin. Most major players in the discipline were there, including some of the people who laid the foundations for all the big models in the 1970s and 1980s. Consequently, many of the presentations discussed the history of crop modelling and the impressive progress that the field has made since its early days. Models originally designed to simulate crop growth at the plot level are now used for large-scale food security assessments and for policy advice up to the global level. The ability of models to simulate crop responses to weather, soil and management has greatly improved and colleagues from all around the world presented a number of very promising results. Gaps in current crop models From an agroforestry perspective, however, the state of the modelling art is quite sobering, especially when it comes to smallholder systems in many developing countries. Almost all convincing applications of crop models focus on simple systems. In most cases, they consider only pure stands of crops grown in monoculture. Simulations of intercropping are rare, and at the conference I didn’t come across any presentations that reported on process-based models that include trees in agricultural landscapes. Even some of the major constraints encountered by farmers around the world are currently not well represented. These include the impacts of pests, weeds, diseases and labour constraints, but also water-related phenomena such as waterlogging and extreme droughts. These are very important problems affecting the productivity of many farms, and they are not considered in the models most crop modelers rely on. Another omission I noticed is that essentially all model applications I saw at the conference focused exclusively on projecting yields. Agroforestry, however, like many other types of production systems, produces a range of other ecosystem services. These include tangible products such as food from trees, fuelwood, medicine, soil fertility and construction materials, and also less visible services such as water cycle regulation, wildlife and pollinator habitat, and cultural identity for people living in farming landscapes. Dangerous simplifications I realize that adding all these complicated features to models will be very challenging. But is it acceptable to base policy advice on models that ignore them? Let’s imagine what advice can arise from such models. If the only inputs my crop model considers are attributes of the crop variety, soil conditions, management and weather, only certain types of recommendations can emerge from them. Basically, these are restricted to advice on crop and seed selection, crop development, and on-farm management measures such as fertilization and irrigation. Such models cannot show the need for better pest control, the importance of labour peaks at certain times of the year, the need for land tenure security, or the benefits from better linking farmers to markets. In short, we should not expect them to deliver advice that accounts for the complex situations many farmers find themselves in. Similarly, if the outputs of our model are restricted to crop yields and ignore other ecosystem services, the advice that their use leads to may end up being rather one-sided. It will place great emphasis on food production but likely fail to consider other objectives of rural development, such as sustainability, resilience, employment, soil conservation and nutrition. Indeed, failure to factor in long-term impacts and off-site effects of interventions has resulted in the unsustainability of many of today’s farming systems. We can observe many negative consequences of this one-sided view, including the pollution of freshwater and ocean systems caused by over-fertilization in mono-cropping systems, or the ecologically and often economically impoverished landscapes that dominate many of the world’s ‘most productive’ agricultural regions. The biggest problem in using models that strongly simplify complex systems is that system features they fail to include may implicitly be valued at zero. But few agricultural experts – including farmers – would agree that biotic stresses (pests, diseases and weeds) have no effects, or that ecosystem services other than yields have no value. So the values that models assign to these processes or services – zero – is most certainly wrong. If all cropping systems produced about the same quantity of ecosystem services, this wouldn’t matter, because inclusion of these services wouldn’t affect our preference for one type of system over another. But there are clear differences. Many agroforestry systems, for instance, produce large amounts of fuelwood, fruits and other foods, fodder and construction materials. They often improve soil fertility, regulate water cycles, reduce wind speeds, conserve soils, sequester carbon and provide shade. Models that do not take into consideration all these contributions systematically undervalue agroforestry systems – and many other system types as well. Instead, they tend to favour high-input monoculture systems that produce high yields but not much else – systems that may even undermine the natural resource base they rely on. The limitations of current crop modelling approaches Crop modelers may – and sometimes do – argue that as the discipline progresses, the current gaps in the models will be filled. But is this a realistic expectation? The ambition so far has been to simulate all important ecological processes that are related to crop growth in a way that allows fairly precise prediction of crop yields. For simple systems, this has been somewhat successful, but can we hope to understand ecological interactions in more complex systems to a comparable degree? And if we can, will such models have huge data requirements that severely restrict their application in practice? I find it hard to imagine a convincing process-based model operating in the way common crop models do that includes the array of constraints many farmers face and the many dimensions of agricultural production that holistic, sustainability-oriented advice to development decision-makers should consider. Such a model would be massively complex and rely on so many input parameters, many of which would be almost impossible to obtain, that it would be essentially unusable. The challenges that crop modelers face also have to do with the unpredictable nature of many drivers that affect farms. For example, crop losses due to agricultural pests are very difficult to predict because pest life cycles can be complex. They can depend on processes at landscape or even coarser scales that crop models don’t normally consider and that have not been studied sufficiently. Models that aim to make precise deterministic predictions cannot adequately account for phenomena for which precise predictions aren’t feasible. In short, modelling strategies relying on precise representation of all relevant processes may be doomed to fail for all but the simplest agricultural systems, and they are unlikely to provide us with comprehensive evaluations of the total value of agricultural impacts that go far beyond simple yield predictions. A fresh view on crop modelling If there is little hope of making precise performance models of complex agricultural systems, can we not model them at all? Well, we may have to think of a different strategy for getting this done. First of all, we may have to accept that precise representation of all important processes is not within reach. This is a serious problem for the way many crop models operate, but it can be overcome if we adopt probabilistic modelling approaches. Probabilistic models do not require precise inputs. They can already give us answers, if we manage to describe how much we know about a variable of interest. We can provide such descriptions in the form of confidence intervals (ranges, in which we’re sure that we’ll find the true values) or probability distributions. Probabilistic models can work with such inputs. Naturally, if we aren’t precise about model inputs, we cannot expect precise outputs. But probabilistic models can also express outputs as probability distributions, which describe the plausible ranges of outcomes that we can expect. If we don’t know much about our systems, such models can only give us rather vague answers, but ones that may help us considerably in improving policy and management decisions. These answers would reflect the limited knowledge that we have, which arguably is preferable to very precise answers relying on numbers in which we have very little confidence. Abandoning precision in crop modelling opens up a number of new opportunities. We may, for example, question the precision with which common crop models describe many of the ecological processes. This precision becomes apparent only when we look under the hood of the models, but it may be worth asking to what extent models rely on best-bet assumptions and empirical relationships that are difficult to defend and may not be universally valid. If we don’t have to be precise, we have the new option of including in our models things to which we can’t assign definite numbers. Going back to the ecosystem services that agroforestry systems provide, we normally can’t pinpoint a precise value for fuelwood production. But we may be able to say that a hectare of a certain tree-based farming system produces anywhere between 1 and 5 tonnes of fuelwood per year. This range then allows us to include fuelwood in production value calculations, and it keeps us from neglecting this important product just because we cannot predict its production with certainty. We can proceed in a similar manner to value other ecosystem services, in order to arrive at a robust range of the Total Economic Value that agricultural systems provide. Basing land-use advice on such ranges would raise the chance that our recommendations not only promote high-yielding cropping systems but also favour equitable and sustainable production practices. Holistic crop modelling is more realistic crop modelling A shift towards a more holistic approach to crop modelling that does justice to the complexity of the modelling challenge, the data limitations we encounter in many places and the unpredictability of many processes could be easier than it may seem. Techniques to address this challenge exist, albeit outside the array of methods that most crop modelers are familiar with. I’ve been working for some time with risk assessment and decision analysis methods, which are designed to support risky decisions on complex systems, about which we have limited knowledge. They address challenges that have much in common with the quest to predict the performance of complex cropping systems for which we are equally far from knowing everything we would like to know. These methods are widely used in many other fields, such as software risk management, oil exploration and public health planning, but not commonly in crop modelling. One of the main principles of decision analysis is that we should consider all factors that seem important for the system we work on. We should integrate everything we know about the system, including data and expert knowledge, but honestly acknowledge the limitations of our knowledge. And we should fully consider our uncertainty rather than basing evaluations on best-bet assumptions. If, after doing this, we are not satisfied with the precision our model provides, we can use procedures known as Value of Informationanalysis to identify the key uncertainties in our model, which we can then address through targeted research. Key techniques of decision analysis are Monte Carlo simulations and Bayesian Network modelling, both of which hold great promise for crop modelling. Such approaches would be a radical departure from the way crop modelling is commonly done today. They would allow us to make performance predictions that are more holistic and as a result more realistic, and expand the range of systems that we can hope to model in the foreseeable future. We would no longer be restricted to yield predictions for very simple systems, but build the capacity to address the concerns of a wider array of farmers and to consider not only crop production but also the host of other ecosystem services that sustainability-oriented land use advice should include. As a result, we can expect wiser policy and management decisions on intervention choices.
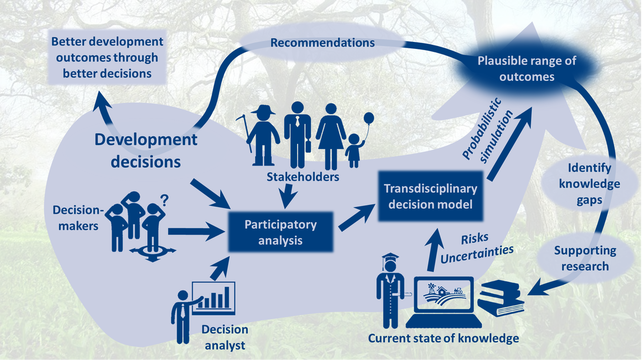
 World Agroforestry Centre (ICRAF) supported decision analysis on exploiting a major aquifer in Kenya World Agroforestry Centre (ICRAF) supported decision analysis on exploiting a major aquifer in Kenya Decision analysis can support us in keeping science relevant If we want impact, we have to influence decision-makers. The most influential research is research that supports good decisions. What information is needed for particular decisions is very variable and difficult to foresee. It requires a thorough analysis that explores all the things the decision-maker needs to factor into a decision, what is already known about these things, and how strongly they affect projected decision outcomes. At the World Agroforestry Centre (ICRAF), we use decision analysis to make such models. Decision analysis is an approach that is optimized for supporting risky decisions on complex systems under uncertainty. It is a tool widely used in the business world and sometimes in policy analysis, but one that is only now entering agricultural development research. To provide tailored support to specific development decisions, we develop causal decision models to simulate the likely impacts of alternative decision options. These models are developed based on various sources of information, but drawing heavily from the inputs of experts, who are convened in a model development workshop. Facilitated by decision analysts, they bring to the table everything they think decision-makers should consider, and assemble these factors into a causal model. Whenever possible, the decision-maker should be a part of this model development group. Once a model exists, the current state of knowledge about all the input variables is assessed. Where no precise numbers exist, which is often the case, values are expressed as confidence intervals or probability distributions. With such inputs, we can run probabilistic simulations, which can convert uncertain inputs into uncertain outputs. This means that they give us plausible ranges of expected outcomes. Sometimes such ranges offer enough guidance already for which decision option holds the greatest promise for impact. Quite often, however, we find that both positive and negative outcomes are possible, when we base our assessment on what we currently know. In such situations, we use ‘Value of Information analysis’ to determine which knowledge gaps we should do research on. Normally, there are a few variables that carry most of the information value, identifying them as decision-specific research priorities.  A well-managed watershed provides many benefits. Photo: World Agroforestry Centre A well-managed watershed provides many benefits. Photo: World Agroforestry Centre Holistic system valuation through Decision Analysis
Decision analysis also has a role in ensuring environmental sustainability is taken into account as we increase food production. We have to get better at considering the value of all environmental services in our decision-making. Crop yields, surely, cannot be all that matters. But considering things like hydrologic services, biodiversity conservation or even the cultural or spiritual value of a farm is difficult, because these cannot be as readily measured as the crop that is harvested. That is why all too often, we let the lack of a precise number lead us to not counting these services at all. But that is like saying their value is zero, which is obviously not the case. To tackle this issue we need to embrace working with ranges rather than precise numbers for everything. We can, for instance, come up with plausible ranges of values for ecosystem services that accommodate different perspectives or different people’s estimates. These ranges can then be used for cost-benefit calculations. We then, of course, do not get precise numbers as the result of such calculations, but also ranges, which again may include high and low values. We still wouldn’t know which precise number to pick, but the ranges (which are really probability distributions) would allow us to compare the relative benefits of, say, different land use options in a holistic way – a way that considers all the environmental services. By taking the system as a whole, we will probably come to realize that multifunctional agriculture with trees, from which farmers gain benefits such as fuelwood, shade and timber, offers more value than a monoculture, even though the latter might have higher crop yields. But we can only come to this conclusion if we adopt a holistic view on systems that considers all the services they provide. Through its capability to consider ecosystem services we cannot quantify precisely, decision analysis can greatly support the causes of productivity, multifunctionality, and sustainability.  Photo Credit: Anne-Lise Heinrichs/Flickr. Photo Credit: Anne-Lise Heinrichs/Flickr. By Eike Luedeling and Keith Shepherd As part of WLE's partnership with The Economist Events' Sustainability Summit this March in London, Thrive is publishing a series of posts that discuss the role science plays in catalyzing shifts toward sustainability in the private sector and beyond. In this blog post, Eike Luedeling and Keith Shepherd, World Agroforestry Centre, explore how sustainability can be evaluated to improve decisions in development and business. This blog was also published here. The scientific community has been on a quest to measure sustainability for decades, and the search for appropriate indicators has intensified with the arrival of the Sustainable Development Goals (SDGs). The struggle to identify appropriate metrics reminds us that sustainability is an awfully difficult thing to measure. This is mainly due to two key characteristics of the concept: First, definitions of sustainability – at least those that still bear resemblance to the origins of the concept – refer to the ability of systems to maintain their major functions over time. If we take this idea seriously, we cannot credibly measure sustainability without anticipating what will happen to system performance in the future. Since it is difficult to take samples of future soils, interview future generations or conduct controlled trials under future climate conditions, many of the classic tools of science are of little use in exploring this key dimension of sustainability. Second, we have come to realize that assessing sustainability requires consideration of ecological, economic and social dimensions, and that each of these consists of many sub-components, all of which are somewhat complicated and often very site specific. This complexity makes comprehensive measurement of sustainability a daunting task, especially when we hope to measure it with globally valid indicators. Risks and uncertainty are part of the game Both of these peculiarities of sustainability – the need to consider the future and complexity of the definition – imply that we’ll have a very hard time measuring sustainability with precision. Since we never have unlimited resources for such an assessment, and we often don’t fully understand the systems we’re dealing with, uncertainties will persist and need to be considered. Because, obviously, there is no way of completely eliminating uncertainty about the future, except to wait for it to happen. Faced with these challenges, it is helpful to return to the ultimate objective of introducing sustainability as a guiding principle for development: Its purpose is not to assess how sustainable systems are, but to make development more sustainable. This distinction is important because it shifts the focus away from the monumental task of assessing the future performance of often complex systems. Instead, it directs our attention to the need to anticipate the effects of our actions – the impacts of the decisions we make – on long-term system performance. So how does this make things easier? If we focus on evaluating the impacts of decisions, we can concentrate on the dimensions of sustainability that our decisions are likely to influence, rather than spending time and money measuring dimensions that will not be affected. We now ask whether the ideas we’re considering make the system more or less sustainable, rather than wonder about absolute levels of current and future sustainability. This is often much easier to determine than how sustainable the present system is. More importantly, a focus on decisions allows us to harness approaches based on decision theory, an age-old discipline concerned with precisely the challenge of supporting decisions under uncertainty. In particular the field of decision analysis – decision theory’s practice-oriented cousin – has produced pragmatic approaches that can be leveraged for making development more sustainable. Decision analysis for supporting sustainable development As we’ve recently outlined in Nature’s Policy forum, decision analysis approaches aim to advise decision makers on the most rational course of action when they face decisions involving risks and uncertainties. Since most decisions must be made without extensive accompanying research, this advice is given based on the current state of knowledge, which is distilled from all available sources of information, including expert knowledge. When decision analysts are able to express their understanding of system dynamics and system parameters in ways that allow consideration of uncertainty, they can produce probabilistic models of decision outcomes. Or, in other words, they can make predictions that illustrate the range of possible outcomes, given our uncertainty about the systems we’re trying to influence. Considerable potential lies in the ability of many decision analysis methods to deal with variables we don’t have much information on. This is often the case for the social or ecological dimensions of sustainability, and it is one of the main reasons for the frequent omission of these dimensions from business models for development interventions. In the absence of hard data, decision analysis gives us the option of estimating, say, that a decision will generate employment for between 100 and 500 people and reduce infant mortality by 5 to 15%. This is pretty imprecise, but it is more useful than reducing business cases to what we have data for and ignoring everything else. The capacity to work with value ranges, rather than needing precise numbers, also opens opportunities for monetizing non-monetary system outcomes in a way that doesn’t come across as arbitrary and potentially biased. This feature of decision analysis allows us, for example, to consider the reputation gain for a company that supports sustainable land management practices in business models. Supporting concrete decisions The most important benefit of using decision analysis approaches for strengthening sustainability is that it actually generates information that helps people make better decisions. It is decisions, after all, that ultimately generate positive outcomes. Decision-specific assessments offer much better guidance to people making these decisions than any studies aiming to quantify the current or future state of system sustainability. They also allow people, through procedures known as value of information analysis, to highlight decision-specific knowledge gaps that should be narrowed to ensure robust recommendations. These knowledge gaps can sometimes be found in surprising places. For example, analyses have revealed that the business case of a company supplying fresh water to a city in northern Kenyadepended to a considerable degree on whether the pipeline project would be undermined by political interference. In this case, the analyses revealed that increased clarity on political risks was a critical information need to be addressed before moving ahead with the pipeline. Similarly, where businesses aim to work with smallholder farmers to establish tree-based value chains, e.g., for fruit or timber production, studying farmers’ time preference – their ability to wait for income in the future – may give a better indication of the viability of the business model than detailed soil and tree performance analyses would. At the World Agroforestry Centre, an international research-for-development institute in Nairobi, Kenya, we are deploying decision analysis methods in agricultural development, with very promising results so far. We find that such approaches can be instrumental in breaking the indecision that often results from the combination of complexity and data scarcity by instead focusing on what is actually known, and using this information to project plausible decision impact prospects. We believe that large-scale introduction of such approaches into planning of development work, as well as private and public sector projects, could make a huge contribution to progressing toward sustainability.  Faster and efficient tools for better decision making. Photo: ACIAR project site, Rwanda/ICRAF Faster and efficient tools for better decision making. Photo: ACIAR project site, Rwanda/ICRAF By Eike Luedeling, Lutz Göhring, Keith Shepherd
This post was first published on ICRAF's blog here. Big decisions with limited information Deciding on big issues without enough information has just gotten a little bit easier. This step forward is facilitated by the release of the decisionSupport R package by the Land Health Decisions group at the World Agroforestry Centre (ICRAF), supported by the CGIAR Research Program on Water, Land and Ecosystems. One of the main reasons why many decisions are difficult to make is that we don’t know enough to be absolutely sure about their consequences. We also don’t normally have enough time or money to collect a lot of information. But even where we’re able to ‘do the research’, some uncertainty still remains, because there are many things about the world and the future that we simply can’t know. How can we make decisions in such an environment? Of course we can rely on our gut feeling alone, but this isn’t always acceptable. Especially for big decisions in international development, we normally expect a more robust approach, since such decisions can affect millions of people, vast areas and enormous amounts of money. Unfortunately, many of these same decisions are made in areas that are particularly data-scarce, such as rural Africa. Lessons from the corporate world Of course, development is not alone with such challenges. Businesses around the world struggle with similar situations all the time. Decisions must be made without perfect knowledge, and profits and jobs depend on managers making these decisions right. This is why at ICRAF, we have adopted business analysis approaches for aiding decisions in international development. Douglas Hubbard’s Applied Information Economics concept served as a blueprint for our first stab at this. In this concept, business analysts develop mathematical impact models for a decision together with decision-makers, who are encouraged to put into the model everything they find important. Rather than going off on a multi-year multi-million dollar research journey, analysts work together with technical experts to quantify the current state of uncertainty on all the unknown variables in the model. What do we know now, before we take any measurements? When we do an honest appraisal of what we really know for certain, there isn’t a lot – at least when we try to pin precise numbers to things. But what we can always do – at least after learning a few estimation techniques and maybe doing a quick web search – is come up with two numbers that are very likely to bracket the real value. We can find one value that is certainly lower and one that is certainly higher than the value we’re looking for. For some mathematical techniques, this is sufficient. These have somewhat obscure names like Monte Carlo simulation or Bayesian Networks, and they are a bit more difficult to use than standard Excel spreadsheets. But if we manage to apply them to our decision problems, they can produce for us a range of decision outcomes that we should prepare for. They can give us an impression of the worst and the best decision results that can realistically happen. Maximizing expected welfare Every decision requires us to answer the question What shall be done? We can only give an answer, if we have clarity on what it actually is that we’re trying to accomplish. Often, we may simply want to maximize our financial profits. In most cases in development, however, things are more complicated and success or failure of a project is determined by a wider range of measures, which are often interrelated and may even be in conflict with each other. Economists call the compound measure that combines all these variables the ‘welfare function’. According to this principle, decision-makers strive to maximize their expected welfare, which is determined by his or her values and preferences. Decision models are mathematical representations of all the variables and processes that determine the welfare arising from a decision. Sometimes knowing the range of plausible welfare outcomes is enough. If all conceivable consequences of making a decision a certain way are better than those of the alternative course of action, we can safely go ahead and decide. Things get a bit trickier when the results are not so clear – if our first analysis tells us that the results of choosing decision alternative A over B can have both positive and negative welfare outcomes. The value of information We’re always smarter about what would have been the right decision, after we observe the actual outcome. We often wish that we had decided differently, but this is never an option. Our decision models attempt to reduce the frequency of such frustrations, but a certain chance of negative welfare outcomes often remains. If the decision is important and we don’t feel like the analysis so far has given us enough guidance, we may want to take measures to reduce our uncertainty even further. But how? Let’s turn to the next step in our analysis framework: the value of information. The value of information gives an impression of just how much our uncertainty about different variables limits our confidence that we’re making the right decision. It tells us, on which variables measurements would produce the greatest gain in certainty that we’re taking the right decision. The value of information normally varies greatly between the various variables in a model, and there are often a few that stand out clearly from the rest. Measurements on these factors can often be very effective for vastly improving the decision. Making methods accessible We have used this framework in a few cases already, for example for developing a Global Intervention Decision Model, or for analyzing the prospects for building a freshwater pipeline in Kenya. So far the methods we have used, and are continuing to improve, have been useful only to us and a few of our stakeholders. But they can only have the desired effects of improving decisions on a larger scale, if everyone can use them. A first step in this is the publication of our methods as an open-source extension package for the R programming language. The package decisionSupport has just become available on the CRAN repository, the standard download hub for R packages. In addition to the code, we have added detailed documentation of all functions, so that we hope that the tools will find a wide audience. And we’ve attempted to make their use as convenient as possible. Please check decisionSupport out, and let us know what you think. This package is only one step on our journey towards establishing the use of decision analysis tools in international development. We will therefore be grateful for any comments that will help us make the tools more user-friendly. A constructive approach to knowledge gaps Admittedly, some residual difficulty remains in making big decisions without adequate information, even now that our tools are available. But things get easier if we shift the focus from what we don’t know to what we actually do know. Systematically assessing this and then using this knowledge in a structured way that honestly acknowledges our uncertainties can go a long way to making better and more transparent decisions. This is what our tool aims to achieve, and we hope that it can make a contribution to overcoming the decision paralysis often caused by lack of data.  Focus group discussions in Madogashe, Kenya, where stakeholders are engaged in sharing their opinion regarding the pipeline project. Photo: Sarah Ogalleh/CETRAD Focus group discussions in Madogashe, Kenya, where stakeholders are engaged in sharing their opinion regarding the pipeline project. Photo: Sarah Ogalleh/CETRAD By Eike Luedeling, Jan De Leeuw, and Keith Shepherd
This blog post was originally published as part of the ‘Talking Science’ Blog Competition. It's also been published on WLE's Thrive blog here. Making better development decisions with decision analysis tools Making decisions is difficult. Most of us spend a lot of time procrastinating about decisions in our everyday lives, struggling to weigh pros and cons and thinking through ‘what-if’ scenarios. For big decisions, like buying a car, we may do a bit of research; but most of the time, we simply follow our gut feeling as a guide. This is okay, as long as we’re right most of the time, and the potential harm from taking a bad decision is limited. Big development decisions But do we want those who make decisions on some of the biggest issues in development to also follow their gut instinct? Such decisions can easily involve millions – even billions – of taxpayer dollars. Poor decision-making can make this money evaporate without much effect. Worse even, effects can be negative if people adjust their behavior in the hope of new opportunities that don’t materialize. Most of us probably expect big decisions to be informed by more ‘scientific’ methods than we normally use. But especially in many developing countries, there is little reliable data on important issues, making it hard to base decisions on what we typically call ‘facts’. In almost all cases, the impact of a decision simply can’t be forecast with much certainty, because various ‘unpredictable’ factors affect the system we’re trying to influence. Such factors could be the weather, climate change, the political environment or simply people’s enthusiasm for a new idea. It would be desirable for decision-makers to consider all these factors, but we normally can’t gain certainty about all of them. We could do detailed research on one or two factors, but would that be sufficient for better decision-making? Business analysis methods The challenges faced by decision-makers in development aren’t new or unique. Decision-makers everywhere decide on big risky projects in the face of imperfect information. And business analysts have developed useful tools to help them. At the World Agroforestry Centre, we’re exploring and adapting such approaches for development contexts. We use participatory processes to develop models that show the impacts of decisions. Together with a team of stakeholders, i.e. all parties affected by the decision, we think through all implications of a decision, including all its costs and benefits, as well as all risks that could undermine the intended decision impacts. We encourage stakeholders to bring up everything they consider important, regardless of how easily they think it can be measured. This approach allows the inclusion of environmental and social impacts, risks to decision implementation, and other issues for which we don’t have hard data and which are therefore often not adequately considered during decision-making. This enables us to do more comprehensive (or ‘holistic’) forecasts of decision impacts than approaches that consider only variables that can precisely be quantified. We translate stakeholder inputs into mathematical equations, and the team agrees on plausible ranges for all variables. The model can then give us a range – or rather a probability distribution – of plausible decision outcomes. We can also identify the uncertain variables that we would benefit most from measuring. We can therefore make forecasts of decision impacts in the face of our current uncertainty, and we can define priorities for decision-oriented research. Water for Wajir One of the first applications of our approach was a proposed pipeline project in northern Kenya. In this project, the future water supply for the rapidly growing city of Wajir is proposed to be ensured by tapping a politically sensitive aquifer near the town of Habaswein, about 110 km away, and piping water to Wajir. Many residents of Habaswein are strongly opposed to this idea, fearing for the reliability of their water supply. Our decision analysis showed that hydrological risks were indeed considerable, but they were trumped by the risk of political interference due to inadequate benefit sharing. The greatest uncertainties were related to valuing the benefits from better water supply (e.g. regarding reduced infant mortality), as well as the financial viability of operating the water supply system. This analysis allowed us to recommend modifications to the project design to help mitigate risks and enhance the project’s probability of success. The way forward Our initial experiences using business analysis methods in development contexts have been very encouraging. Stakeholder feedback was generally positive, and many stated that being involved in the research process improved their understanding of the decisions under consideration. The knowledge gap analysis highlighted critical issues for research that would likely remain unstudied without our kind of analysis. We think that our approach can improve decision-making in development and facilitate better allocation of development and research funds. More effective use of scarce development resources can then take developing countries one step further towards meeting their Sustainable Development Goals. |

Eike LuedelingSenior Decision Analyst at the World Agroforestry Centre (ICRAF) in Nairobi and the Center for Development Research (ZEF) in Bonn Archives
October 2017
Categories |

 RSS Feed
RSS Feed